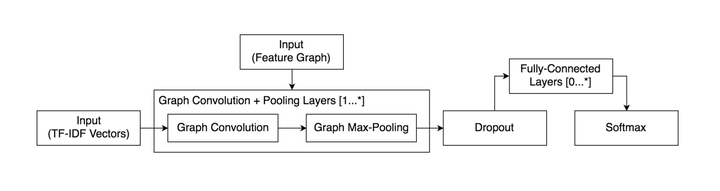
Abstract
Text classification is the task of labeling text data from a predetermined set of thematic labels. It has become of increasing importance in recent years as we generate large volumes of data and require the ability to search through these vast datasets with flexible queries. However, manually labeling text data is an extremely tedious task that is prone to human error. Thus, text classification has become a key focus of machine learning research, with the goal of producing models that are more efficient and accurate than traditional methods. The objective of this work is to rigorously compare the performance of current text classification techniques, from standard SVM-based, statistical and multilayer perceptron (MLP) models to recently enhanced deep learning models such as convolutional neural networks and their fusion with graph theory. Extensive numerical experiments on three major text classification datasets (Rotten Tomatoes Sentence Polarity, 20 Newsgroups and Reuters Corpus Volume 1) revealed two results. First, graph convolutional neural networks perform with greater or similar test accuracy when compared to standard convolutional neural networks, SVM-based models and statistical baseline models. Second, and more surprisingly, simpler MLP models still outperform recent deep learning techniques despite having fewer parameters. This implies that either benchmark datasets like RCV1 containing more than 420,000 documents from 52 classes are not large enough or the representation of text data as tf-idf document vectors is not expressive enough.